Federated Learning for Dummies
June 21, 2023
Federated learning (FL) allows models to be trained collaboratively between different parties (aka clients) able to contribute their data to do so. Federated learning works as follows.
- Each client receives a global model from a central manager (centralised federated learning) or models from other client(s) (decentralised or distributed federated learning),
- Clients train local models with their own data, and send them back to the admin node or to their network,
- The admin node consolidates the learning shared by all nodes and shares it back with the clients to start a new training process (centralised), or nodes share their local model with their network (de centralised).
The data never leaves the client that controls it, but nodes exchange the gradients of the models resulting from local training instead. This approach is in contrast to traditional centralised training in which data from different sources is usually brought together to a single processing node that trains a centralised model based on all the data available.
Let us make an example. Imagine a simple model that calculates (or learns) the average age of the population in a country. In a traditional approach, all the information about individuals’ birth dates is stored in a common database and a query is executed to calculate the average age. Previously, all local registries have shared the information of individuals with the central database on which this calculation is made.
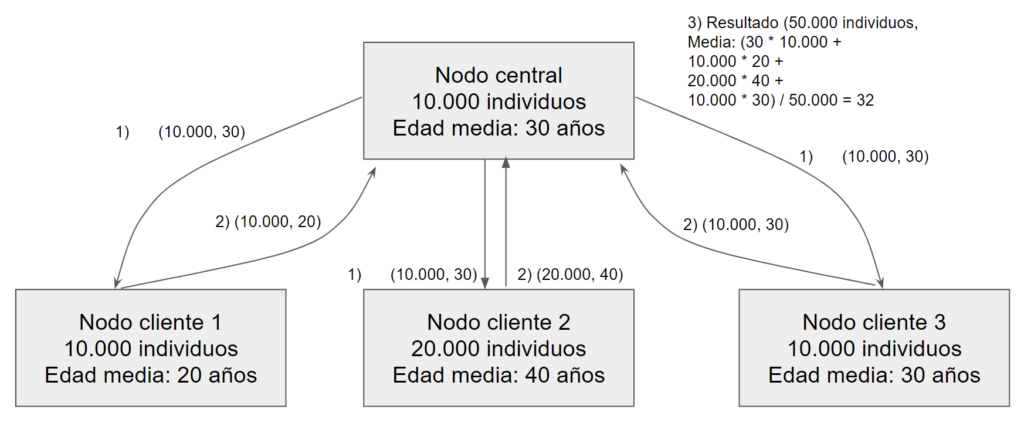
What if we do not want to reveal the age of individuals to this central manager? A possible federated learning approach would be that each district in the country stores the information of people born in that district and act as clients in a FL approach, and one of them would act as the central manager. This central manager would share the information from the global model (step 1), which in this case would be the number of individuals it controls and its local estimate of the average age, basically. In response, local nodes will respond with the number of nodes they control and their mean (step 2). The central node consolidates this information and calculates the result with all nodes (step 3), and can communicate the result (or the new global model) back to all nodes so that they have it.
Figure 1. Simple example of federated learning to calculate the average age of a population
The example is simple and is not intended to capture the full complexity of federated learning, but to give an understanding of the concept behind the term. Federated learning models are often neural networks with thousands of parameters, the inputs change over time, the models may require several rounds of training to reach optimal efficiency, etc.
Federated learning has advantages and poses significant design challenges. The main advantages include (i) protecting data privacy and reducing the risk of security breaches, (ii) reducing network traffic by reducing data traffic, and (iii) distributing knowledge among different nodes. It is therefore being considered for use in sectors and use cases where data privacy is a priority, such as in health sciences. Moreover, it is already being used in practical applications that we use on a daily basis, such as predictive text on mobile phones or facial recognition applications.
Unfortunately, FL can suffer from imprecision in the results obtained, inefficiencies in communication, it involves different types of devices, and it has limitations in cleaning training information and filtering out “rogue” clients, and it must find ways to incentivise clients to collaborate, especially when they are not particularly interested in the final model and only want to contribute data to a task. In addition, several papers have pointed to potential privacy breaches if the manager is able to “infer” information of individuals from the data shared by clients in the training process. In the example above, if clients only control a single individual, then the manager is able to infer this age from the data provided as a result of training the model.
All of these challenges can be managed with proper design. The scientific objectives of the MLEDGE project aim to contribute to overcoming these challenges and improve the state of the art in each of them.