
Aprendizaje Federado para Legos
junio 21, 2023
Los métodos de aprendizaje federado permiten entrenar modelos de forma colaborativa entre diferentes partes (o clientes) que disponen de los datos necesarios para ello. Cada cliente recibe un modelo común de un gestor central (aprendizaje federado centralizado) o de otro(s) cliente(s) (aprendizaje federado descentralizado o distribuido), lo entrena localmente con sus propios datos, y lo vuelve a compartir con la red, que se encarga de consolidar el aprendizaje que han compartido todos los nodos.
Los datos “crudos” nunca abandonan el cliente que los controla, y lo que se intercambian son los cambios en los modelos resultados de los entrenamientos locales. Este enfoque se contrapone al más tradicional entrenamiento centralizado en el que los datos de las diferentes fuentes se suelen llevar a un único punto de procesamiento en el que se utilizan para entrenar este modelo centralizado.
Vamos a explicarlo con un ejemplo simple. Imaginemos un simple modelo que calcula (o aprende) la edad media de la población de un país. En un enfoque tradicional, toda la información de la fecha de nacimiento de los individuos en una base de datos común (por ejemplo, el Registro Civil) y se realiza una consulta para calcular la edad media. Para ello, todos los registros de todos los puntos del país han compartido previamente la información de cada uno de los individuos con la base de datos central sobre la que se realiza este cálculo.
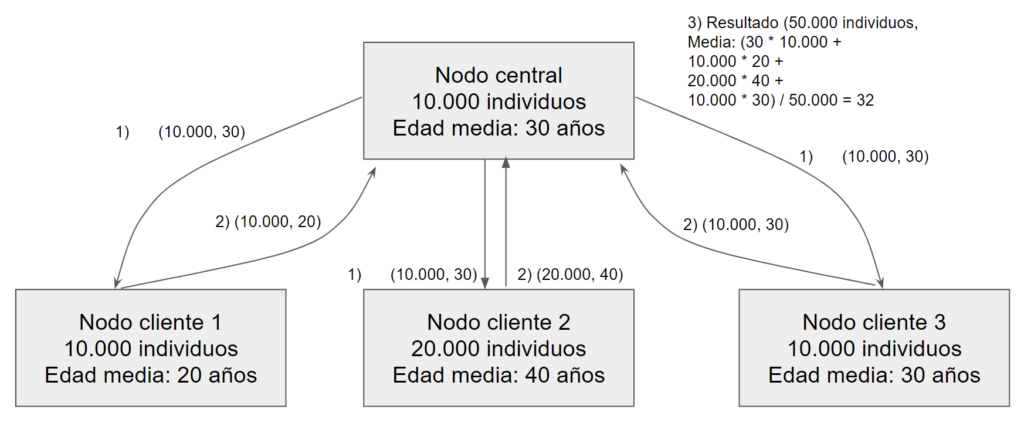
¿Y si no queremos revelar la información de la edad de los individuos a este gestor central? Un posible enfoque de aprendizaje federado sería que cada distrito del país almacenara la información de los nacidos en ese distrito y actuaran como clientes, y uno de ellos actuara como gestor central. Este gestor central compartiría la información del modelo global (paso 1), que en este caso básicamente seria el número de individuos que controla y su cálculo local de la edad media. En respuesta, los nodos locales responden con el número de nodos que controlan y su media (paso 2). El nodo central consolida esta información y calcula el resultado con todos los nodos (paso 3), además puede comunicar de nuevo el resultado (o el nuevo modelo global) a todos los nodos para que dispongan del mismo.
Figura 1. Ejemplo simple de aprendizaje federado para calcular edad media
El ejemplo es simple y no pretende capturar toda la complejidad del aprendizaje federado, sino dar a entender el concepto detrás de este término. Los modelos de aprendizaje federado a menudo son redes neuronales con miles de parámetros, los insumos cambian con el tiempo, los modelos pueden requerir varias rondas de entrenamiento para alcanzar una eficiencia óptima, etc.
El aprendizaje federado tiene ventajas y plantea significativos desafíos de diseño. Como principales ventajas cabe señalar i) que permite proteger la privacidad de los datos y reducir el riesgo de brechas de seguridad, ii) que permite reducir el tráfico en la red al reducir el trasiego de datos y iii) que distribuye el conocimiento entre diferentes nodos. Es por ello que se está pensando en utilizar en sectores y casos de uso donde la privacidad de los datos es prioritaria, como en ciencias de la salud. Además, ya se está utilizando en aplicaciones prácticas que usamos en el día a día como en el texto predictivo de los móviles o en aplicaciones de reconocimiento facial.
Como principales desafíos, el aprendizaje federado puede adolecer de menor precisión, ineficiencias en la comunicación, involucra diferentes tipos de dispositivos, tiene limitaciones a la hora de limpiar la información de entrenamiento y filtrar clientes “deshonestos”, y debe garantizar los incentivos de las diferentes partes implicadas en el entrenamiento, especialmente cuando estas no están especialmente interesadas en el modelo final y tan solo desean aportar datos. Adicionalmente, diversos trabajos han apuntado a potenciales brechas de privacidad si el gestor es capaz “inferir” la información de los clientes. En el ejemplo anterior, si los clientes tienen información de un solo individuo entonces en gestor es capaz de inferir esta edad con los datos que le entrega como resultado del entrenamiento del modelo.
Todos estos desafíos se pueden gestionar con un adecuado diseño. Los objetivos científicos del proyecto MLEDGE tienen como objetivo contribuir a superar estos desafíos y mejorar el estado del arte en cada uno de ellos.